整理了Pandas的一些基础用法,以前学习的时候写在Jupyter上。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
s=pd.Series([1,2,3,np.nan,5,6])
s
0 1.0
1 2.0
2 3.0
3 NaN
4 5.0
5 6.0
dtype: float64
dates=pd.date_range("20170101",periods=20)
dates
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07', '2017-01-08',
'2017-01-09', '2017-01-10', '2017-01-11', '2017-01-12',
'2017-01-13', '2017-01-14', '2017-01-15', '2017-01-16',
'2017-01-17', '2017-01-18', '2017-01-19', '2017-01-20'],
dtype='datetime64[ns]', freq='D')
np.random.randint(10,size=(2,5))
array([[6, 4, 1, 8, 0],
[0, 4, 3, 0, 1]])
df1=pd.DataFrame(np.random.randn(20,4),index=dates,columns=["a","b","c","d"])
df1
|
a |
b |
c |
d |
| 2017-01-01 |
-0.731296 |
0.308452 |
1.550586 |
0.022510 |
| 2017-01-02 |
0.011909 |
-2.604560 |
-0.328210 |
-0.831059 |
| 2017-01-03 |
1.016461 |
-0.340761 |
1.399342 |
1.435456 |
| 2017-01-04 |
-0.610496 |
-0.962359 |
-0.397980 |
0.833718 |
| 2017-01-05 |
1.298400 |
-0.148515 |
-1.366670 |
0.718973 |
| 2017-01-06 |
0.265090 |
0.490953 |
1.048929 |
-0.611945 |
| 2017-01-07 |
-0.718811 |
1.640064 |
-1.063297 |
-1.092510 |
| 2017-01-08 |
-0.686471 |
0.541123 |
0.415082 |
0.368303 |
| 2017-01-09 |
0.352406 |
-0.061781 |
1.385387 |
0.240791 |
| 2017-01-10 |
-0.750252 |
-0.353765 |
0.163297 |
-0.706397 |
| 2017-01-11 |
1.707390 |
1.000258 |
0.717216 |
-0.566941 |
| 2017-01-12 |
-0.341289 |
0.742661 |
-1.820184 |
-0.182327 |
| 2017-01-13 |
-0.583300 |
-0.490837 |
-0.611798 |
-1.238514 |
| 2017-01-14 |
0.285966 |
1.219942 |
1.679262 |
0.170911 |
| 2017-01-15 |
-0.100615 |
-0.111391 |
1.827916 |
0.359999 |
| 2017-01-16 |
0.834599 |
0.214739 |
-0.868497 |
0.637817 |
| 2017-01-17 |
1.233904 |
-0.296525 |
-0.218316 |
0.651542 |
| 2017-01-18 |
2.211547 |
1.652226 |
1.415402 |
-1.023644 |
| 2017-01-19 |
0.176992 |
0.228890 |
0.844449 |
1.267496 |
| 2017-01-20 |
-0.242708 |
-0.792746 |
0.377210 |
0.521628 |
df2=pd.DataFrame({"A":range(11,20),"B":pd.Timestamp("20170101"),"C":pd.Series(np.random.random(9),index=range(11,20)),"D":np.array([i for i in range(1,10)]),
"E":pd.Categorical(["one","two","three","four","five","six","seven","eight","nine"])})
df2
|
A |
B |
C |
D |
E |
| 11 |
11 |
2017-01-01 |
0.115527 |
1 |
one |
| 12 |
12 |
2017-01-01 |
0.966706 |
2 |
two |
| 13 |
13 |
2017-01-01 |
0.627952 |
3 |
three |
| 14 |
14 |
2017-01-01 |
0.858634 |
4 |
four |
| 15 |
15 |
2017-01-01 |
0.512081 |
5 |
five |
| 16 |
16 |
2017-01-01 |
0.986166 |
6 |
six |
| 17 |
17 |
2017-01-01 |
0.963712 |
7 |
seven |
| 18 |
18 |
2017-01-01 |
0.754798 |
8 |
eight |
| 19 |
19 |
2017-01-01 |
0.184086 |
9 |
nine |
基础操作
df2.head()
|
A |
B |
C |
D |
E |
| 11 |
11 |
2017-01-01 |
0.115527 |
1 |
one |
| 12 |
12 |
2017-01-01 |
0.966706 |
2 |
two |
| 13 |
13 |
2017-01-01 |
0.627952 |
3 |
three |
| 14 |
14 |
2017-01-01 |
0.858634 |
4 |
four |
| 15 |
15 |
2017-01-01 |
0.512081 |
5 |
five |
df2.tail(2)
|
A |
B |
C |
D |
E |
| 18 |
18 |
2017-01-01 |
0.754798 |
8 |
eight |
| 19 |
19 |
2017-01-01 |
0.184086 |
9 |
nine |
df2.index
Int64Index([11, 12, 13, 14, 15, 16, 17, 18, 19], dtype='int64')
df2.columns
Index([u'A', u'B', u'C', u'D', u'E'], dtype='object')
df2.values
array([[11L, Timestamp('2017-01-01 00:00:00'), 0.11552714551146004, 1,
'one'],
[12L, Timestamp('2017-01-01 00:00:00'), 0.9667064772135637, 2, 'two'],
[13L, Timestamp('2017-01-01 00:00:00'), 0.6279515096467739, 3,
'three'],
[14L, Timestamp('2017-01-01 00:00:00'), 0.8586339869062394, 4,
'four'],
[15L, Timestamp('2017-01-01 00:00:00'), 0.5120808880213029, 5,
'five'],
[16L, Timestamp('2017-01-01 00:00:00'), 0.9861662616379155, 6, 'six'],
[17L, Timestamp('2017-01-01 00:00:00'), 0.9637117377995325, 7,
'seven'],
[18L, Timestamp('2017-01-01 00:00:00'), 0.7547980447750812, 8,
'eight'],
[19L, Timestamp('2017-01-01 00:00:00'), 0.1840863987352963, 9,
'nine']], dtype=object)
df2.describe()
|
A |
C |
D |
| count |
9.000000 |
9.000000 |
9.000000 |
| mean |
15.000000 |
0.663296 |
5.000000 |
| std |
2.738613 |
0.332958 |
2.738613 |
| min |
11.000000 |
0.115527 |
1.000000 |
| 25% |
13.000000 |
0.512081 |
3.000000 |
| 50% |
15.000000 |
0.754798 |
5.000000 |
| 75% |
17.000000 |
0.963712 |
7.000000 |
| max |
19.000000 |
0.986166 |
9.000000 |
df2.T
|
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
| A |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
| B |
2017-01-01 00:00:00 |
2017-01-01 00:00:00 |
2017-01-01 00:00:00 |
2017-01-01 00:00:00 |
2017-01-01 00:00:00 |
2017-01-01 00:00:00 |
2017-01-01 00:00:00 |
2017-01-01 00:00:00 |
2017-01-01 00:00:00 |
| C |
0.115527 |
0.966706 |
0.627952 |
0.858634 |
0.512081 |
0.986166 |
0.963712 |
0.754798 |
0.184086 |
| D |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| E |
one |
two |
three |
four |
five |
six |
seven |
eight |
nine |
df2.sort_index(axis=1,ascending=False)
|
E |
D |
C |
B |
A |
| 11 |
one |
1 |
0.115527 |
2017-01-01 |
11 |
| 12 |
two |
2 |
0.966706 |
2017-01-01 |
12 |
| 13 |
three |
3 |
0.627952 |
2017-01-01 |
13 |
| 14 |
four |
4 |
0.858634 |
2017-01-01 |
14 |
| 15 |
five |
5 |
0.512081 |
2017-01-01 |
15 |
| 16 |
six |
6 |
0.986166 |
2017-01-01 |
16 |
| 17 |
seven |
7 |
0.963712 |
2017-01-01 |
17 |
| 18 |
eight |
8 |
0.754798 |
2017-01-01 |
18 |
| 19 |
nine |
9 |
0.184086 |
2017-01-01 |
19 |
df2.sort_values(by="C")
|
A |
B |
C |
D |
E |
| 11 |
11 |
2017-01-01 |
0.115527 |
1 |
one |
| 19 |
19 |
2017-01-01 |
0.184086 |
9 |
nine |
| 15 |
15 |
2017-01-01 |
0.512081 |
5 |
five |
| 13 |
13 |
2017-01-01 |
0.627952 |
3 |
three |
| 18 |
18 |
2017-01-01 |
0.754798 |
8 |
eight |
| 14 |
14 |
2017-01-01 |
0.858634 |
4 |
four |
| 17 |
17 |
2017-01-01 |
0.963712 |
7 |
seven |
| 12 |
12 |
2017-01-01 |
0.966706 |
2 |
two |
| 16 |
16 |
2017-01-01 |
0.986166 |
6 |
six |
通过标签选择
loc与at相似,但是at只能选取一个值,而loc可以选取行或列
df2.loc[11]
A 11
B 2017-01-01 00:00:00
C 0.115527
D 1
E one
Name: 11, dtype: object
df2.loc[:,["A","B"]]
|
A |
B |
| 11 |
11 |
2017-01-01 |
| 12 |
12 |
2017-01-01 |
| 13 |
13 |
2017-01-01 |
| 14 |
14 |
2017-01-01 |
| 15 |
15 |
2017-01-01 |
| 16 |
16 |
2017-01-01 |
| 17 |
17 |
2017-01-01 |
| 18 |
18 |
2017-01-01 |
| 19 |
19 |
2017-01-01 |
df2.loc[13,"C"]
0.62795150964677393
通过位置选择
df2.iloc[0]
A 11
B 2017-01-01 00:00:00
C 0.115527
D 1
E one
Name: 11, dtype: object
df2.iloc[:3,0:3]
|
A |
B |
C |
| 11 |
11 |
2017-01-01 |
0.115527 |
| 12 |
12 |
2017-01-01 |
0.966706 |
| 13 |
13 |
2017-01-01 |
0.627952 |
df2.iloc[[1,3,5],[1,3]]
|
B |
D |
| 12 |
2017-01-01 |
2 |
| 14 |
2017-01-01 |
4 |
| 16 |
2017-01-01 |
6 |
df2.iloc[1,2]
0.96670647721356373
布尔索引
df2[df2.C>0.5]
|
A |
B |
C |
D |
E |
| 12 |
12 |
2017-01-01 |
0.966706 |
2 |
two |
| 13 |
13 |
2017-01-01 |
0.627952 |
3 |
three |
| 14 |
14 |
2017-01-01 |
0.858634 |
4 |
four |
| 15 |
15 |
2017-01-01 |
0.512081 |
5 |
five |
| 16 |
16 |
2017-01-01 |
0.986166 |
6 |
six |
| 17 |
17 |
2017-01-01 |
0.963712 |
7 |
seven |
| 18 |
18 |
2017-01-01 |
0.754798 |
8 |
eight |
df1[ df1 > 0]
|
a |
b |
c |
d |
| 2017-01-01 |
NaN |
0.308452 |
1.550586 |
0.022510 |
| 2017-01-02 |
0.011909 |
NaN |
NaN |
NaN |
| 2017-01-03 |
1.016461 |
NaN |
1.399342 |
1.435456 |
| 2017-01-04 |
NaN |
NaN |
NaN |
0.833718 |
| 2017-01-05 |
1.298400 |
NaN |
NaN |
0.718973 |
| 2017-01-06 |
0.265090 |
0.490953 |
1.048929 |
NaN |
| 2017-01-07 |
NaN |
1.640064 |
NaN |
NaN |
| 2017-01-08 |
NaN |
0.541123 |
0.415082 |
0.368303 |
| 2017-01-09 |
0.352406 |
NaN |
1.385387 |
0.240791 |
| 2017-01-10 |
NaN |
NaN |
0.163297 |
NaN |
| 2017-01-11 |
1.707390 |
1.000258 |
0.717216 |
NaN |
| 2017-01-12 |
NaN |
0.742661 |
NaN |
NaN |
| 2017-01-13 |
NaN |
NaN |
NaN |
NaN |
| 2017-01-14 |
0.285966 |
1.219942 |
1.679262 |
0.170911 |
| 2017-01-15 |
NaN |
NaN |
1.827916 |
0.359999 |
| 2017-01-16 |
0.834599 |
0.214739 |
NaN |
0.637817 |
| 2017-01-17 |
1.233904 |
NaN |
NaN |
0.651542 |
| 2017-01-18 |
2.211547 |
1.652226 |
1.415402 |
NaN |
| 2017-01-19 |
0.176992 |
0.228890 |
0.844449 |
1.267496 |
| 2017-01-20 |
NaN |
NaN |
0.377210 |
0.521628 |
df2[df2['E'].isin(["one","six"])]
|
A |
B |
C |
D |
E |
| 11 |
11 |
2017-01-01 |
0.115527 |
1 |
one |
| 16 |
16 |
2017-01-01 |
0.986166 |
6 |
six |
df2[df2.E.isin(['one',"six"])]
|
A |
B |
C |
D |
E |
| 11 |
11 |
2017-01-01 |
0.115527 |
1 |
one |
| 16 |
16 |
2017-01-01 |
0.986166 |
6 |
six |
s1=pd.Series([111,22,33,44],index=range(12,16))
df2["F"]=s1
df2
|
A |
B |
C |
D |
E |
F |
| 11 |
11 |
2017-01-01 |
0.115527 |
1 |
one |
NaN |
| 12 |
12 |
2017-01-01 |
0.966706 |
2 |
two |
111.0 |
| 13 |
13 |
2017-01-01 |
0.627952 |
3 |
three |
22.0 |
| 14 |
14 |
2017-01-01 |
0.858634 |
4 |
four |
33.0 |
| 15 |
15 |
2017-01-01 |
0.512081 |
5 |
five |
44.0 |
| 16 |
16 |
2017-01-01 |
0.986166 |
6 |
six |
NaN |
| 17 |
17 |
2017-01-01 |
0.963712 |
7 |
seven |
NaN |
| 18 |
18 |
2017-01-01 |
0.754798 |
8 |
eight |
NaN |
| 19 |
19 |
2017-01-01 |
0.184086 |
9 |
nine |
NaN |
df2.at[17,"D"]=3
print df2
df2.iat[1,0]=1
print df2
print len(df2)
df2['F']=np.array([5]*len(df2))
print df2
A B C D E F
11 11 2017-01-01 0.115527 1 one NaN
12 12 2017-01-01 0.966706 2 two 111.0
13 13 2017-01-01 0.627952 3 three 22.0
14 14 2017-01-01 0.858634 4 four 33.0
15 15 2017-01-01 0.512081 5 five 44.0
16 16 2017-01-01 0.986166 6 six NaN
17 17 2017-01-01 0.963712 3 seven NaN
18 18 2017-01-01 0.754798 8 eight NaN
19 19 2017-01-01 0.184086 9 nine NaN
A B C D E F
11 11 2017-01-01 0.115527 1 one NaN
12 1 2017-01-01 0.966706 2 two 111.0
13 13 2017-01-01 0.627952 3 three 22.0
14 14 2017-01-01 0.858634 4 four 33.0
15 15 2017-01-01 0.512081 5 five 44.0
16 16 2017-01-01 0.986166 6 six NaN
17 17 2017-01-01 0.963712 3 seven NaN
18 18 2017-01-01 0.754798 8 eight NaN
19 19 2017-01-01 0.184086 9 nine NaN
9
A B C D E F
11 11 2017-01-01 0.115527 1 one 5
12 1 2017-01-01 0.966706 2 two 5
13 13 2017-01-01 0.627952 3 three 5
14 14 2017-01-01 0.858634 4 four 5
15 15 2017-01-01 0.512081 5 five 5
16 16 2017-01-01 0.986166 6 six 5
17 17 2017-01-01 0.963712 3 seven 5
18 18 2017-01-01 0.754798 8 eight 5
19 19 2017-01-01 0.184086 9 nine 5
df3=df2.copy()
df3["B"]=df3["E"]=6
df3[df3>0]=-df3
print df3
df3.iloc[1:3,1:3]=np.nan
print df3.isnull()
print np.isnan(df3.iloc[1,1])
A B C D E F
11 -11 -6 -0.115527 -1 -6 -5
12 -1 -6 -0.966706 -2 -6 -5
13 -13 -6 -0.627952 -3 -6 -5
14 -14 -6 -0.858634 -4 -6 -5
15 -15 -6 -0.512081 -5 -6 -5
16 -16 -6 -0.986166 -6 -6 -5
17 -17 -6 -0.963712 -3 -6 -5
18 -18 -6 -0.754798 -8 -6 -5
19 -19 -6 -0.184086 -9 -6 -5
A B C D E F
11 False False False False False False
12 False True True False False False
13 False True True False False False
14 False False False False False False
15 False False False False False False
16 False False False False False False
17 False False False False False False
18 False False False False False False
19 False False False False False False
True
reindex() 方法可以对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝
dates=pd.date_range("20170101",periods=len(df2))
print df2
df4=df2.reindex(index=dates,columns=list(df2.columns))
print df4
A B C D E F
11 11 2017-01-01 0.115527 1 one 5
12 1 2017-01-01 0.966706 2 two 5
13 13 2017-01-01 0.627952 3 three 5
14 14 2017-01-01 0.858634 4 four 5
15 15 2017-01-01 0.512081 5 five 5
16 16 2017-01-01 0.986166 6 six 5
17 17 2017-01-01 0.963712 3 seven 5
18 18 2017-01-01 0.754798 8 eight 5
19 19 2017-01-01 0.184086 9 nine 5
A B C D E F
2017-01-01 NaN NaT NaN NaN NaN NaN
2017-01-02 NaN NaT NaN NaN NaN NaN
2017-01-03 NaN NaT NaN NaN NaN NaN
2017-01-04 NaN NaT NaN NaN NaN NaN
2017-01-05 NaN NaT NaN NaN NaN NaN
2017-01-06 NaN NaT NaN NaN NaN NaN
2017-01-07 NaN NaT NaN NaN NaN NaN
2017-01-08 NaN NaT NaN NaN NaN NaN
2017-01-09 NaN NaT NaN NaN NaN NaN
df5=df2.reindex(index=range(14,18),columns=list(df2.columns)+["G"])
print df5
A B C D E F G
14 14 2017-01-01 0.858634 4 four 5 NaN
15 15 2017-01-01 0.512081 5 five 5 NaN
16 16 2017-01-01 0.986166 6 six 5 NaN
17 17 2017-01-01 0.963712 3 seven 5 NaN
df5.loc[14,"C"]=np.nan
print df5
df5=df5.reindex(columns=list(np.array(["A","B","C","D"])))
print df5
df6=df5.dropna(how="any")
print df5
print df6
df7=df5.fillna(value=1111)
print df7
A B C D E F G
14 14 2017-01-01 NaN 4 four 5 NaN
15 15 2017-01-01 0.512081 5 five 5 NaN
16 16 2017-01-01 0.986166 6 six 5 NaN
17 17 2017-01-01 0.963712 3 seven 5 NaN
A B C D
14 14 2017-01-01 NaN 4
15 15 2017-01-01 0.512081 5
16 16 2017-01-01 0.986166 6
17 17 2017-01-01 0.963712 3
A B C D
14 14 2017-01-01 NaN 4
15 15 2017-01-01 0.512081 5
16 16 2017-01-01 0.986166 6
17 17 2017-01-01 0.963712 3
A B C D
15 15 2017-01-01 0.512081 5
16 16 2017-01-01 0.986166 6
17 17 2017-01-01 0.963712 3
A B C D
14 14 2017-01-01 1111.000000 4
15 15 2017-01-01 0.512081 5
16 16 2017-01-01 0.986166 6
17 17 2017-01-01 0.963712 3
相关操作
print df7.mean()
A 15.50000
C 278.36549
D 4.50000
dtype: float64
print df7.mean(1)
14 376.333333
15 6.837360
16 7.662055
17 6.987904
dtype: float64
dates=pd.date_range("2017-01-01",periods=4)
print dates
s2=pd.Series(range(0,len(dates)),index=dates).shift(2)
print s2
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04'], dtype='datetime64[ns]', freq='D')
2017-01-01 NaN
2017-01-02 NaN
2017-01-03 0.0
2017-01-04 1.0
Freq: D, dtype: float64
#sub Equivalent to dataframe - other, but with support to substitute a fill_value for missing data
#in one of the inputs.
dates=pd.date_range("2017-01-01",periods=4)
df7=df7.set_index(dates)
df7.iloc[3,0]=np.nan
df7.iloc[2,2]=np.nan
df7["F"]=np.nan
df7["B"]=13
print df7
df7=df7.sub(s2,axis="index")
print df7
A B C D F
2017-01-01 14.0 13 1111.000000 4 NaN
2017-01-02 15.0 13 0.512081 5 NaN
2017-01-03 16.0 13 NaN 6 NaN
2017-01-04 NaN 13 0.963712 3 NaN
A B C D F
2017-01-01 NaN NaN NaN NaN NaN
2017-01-02 NaN NaN NaN NaN NaN
2017-01-03 16.0 13.0 NaN 6.0 NaN
2017-01-04 NaN 12.0 -0.036288 2.0 NaN
a = np.array([[11,24,37], [41,51,61]])
print a
print np.cumsum(a)
print np.cumsum(a,axis=0)
print np.cumsum(a,axis=1)
[[11 24 37]
[41 51 61]]
[ 11 35 72 113 164 225]
[[11 24 37]
[52 75 98]]
[[ 11 35 72]
[ 41 92 153]]
print df1
df1.apply(np.cumsum)
a b c d
2017-01-01 -0.731296 0.308452 1.550586 0.022510
2017-01-02 0.011909 -2.604560 -0.328210 -0.831059
2017-01-03 1.016461 -0.340761 1.399342 1.435456
2017-01-04 -0.610496 -0.962359 -0.397980 0.833718
2017-01-05 1.298400 -0.148515 -1.366670 0.718973
2017-01-06 0.265090 0.490953 1.048929 -0.611945
2017-01-07 -0.718811 1.640064 -1.063297 -1.092510
2017-01-08 -0.686471 0.541123 0.415082 0.368303
2017-01-09 0.352406 -0.061781 1.385387 0.240791
2017-01-10 -0.750252 -0.353765 0.163297 -0.706397
2017-01-11 1.707390 1.000258 0.717216 -0.566941
2017-01-12 -0.341289 0.742661 -1.820184 -0.182327
2017-01-13 -0.583300 -0.490837 -0.611798 -1.238514
2017-01-14 0.285966 1.219942 1.679262 0.170911
2017-01-15 -0.100615 -0.111391 1.827916 0.359999
2017-01-16 0.834599 0.214739 -0.868497 0.637817
2017-01-17 1.233904 -0.296525 -0.218316 0.651542
2017-01-18 2.211547 1.652226 1.415402 -1.023644
2017-01-19 0.176992 0.228890 0.844449 1.267496
2017-01-20 -0.242708 -0.792746 0.377210 0.521628
|
a |
b |
c |
d |
| 2017-01-01 |
-0.731296 |
0.308452 |
1.550586 |
0.022510 |
| 2017-01-02 |
-0.719387 |
-2.296108 |
1.222376 |
-0.808550 |
| 2017-01-03 |
0.297075 |
-2.636869 |
2.621718 |
0.626906 |
| 2017-01-04 |
-0.313422 |
-3.599228 |
2.223738 |
1.460624 |
| 2017-01-05 |
0.984978 |
-3.747743 |
0.857069 |
2.179597 |
| 2017-01-06 |
1.250069 |
-3.256790 |
1.905998 |
1.567652 |
| 2017-01-07 |
0.531258 |
-1.616726 |
0.842700 |
0.475142 |
| 2017-01-08 |
-0.155213 |
-1.075604 |
1.257782 |
0.843444 |
| 2017-01-09 |
0.197193 |
-1.137385 |
2.643169 |
1.084235 |
| 2017-01-10 |
-0.553059 |
-1.491150 |
2.806466 |
0.377838 |
| 2017-01-11 |
1.154331 |
-0.490892 |
3.523682 |
-0.189103 |
| 2017-01-12 |
0.813042 |
0.251769 |
1.703498 |
-0.371430 |
| 2017-01-13 |
0.229742 |
-0.239067 |
1.091700 |
-1.609944 |
| 2017-01-14 |
0.515708 |
0.980875 |
2.770962 |
-1.439033 |
| 2017-01-15 |
0.415093 |
0.869484 |
4.598878 |
-1.079034 |
| 2017-01-16 |
1.249693 |
1.084223 |
3.730380 |
-0.441217 |
| 2017-01-17 |
2.483597 |
0.787698 |
3.512064 |
0.210325 |
| 2017-01-18 |
4.695144 |
2.439923 |
4.927466 |
-0.813319 |
| 2017-01-19 |
4.872136 |
2.668814 |
5.771915 |
0.454177 |
| 2017-01-20 |
4.629428 |
1.876068 |
6.149125 |
0.975805 |
df1.apply(lambda x:x.max()-x.min())
a 2.961799
b 4.256786
c 3.648100
d 2.673969
dtype: float64
s3=pd.Series(np.random.randint(0,7,size=10))
print s3
#Returns object containing counts of unique values.
s3.value_counts()
0 1
1 3
2 3
3 3
4 4
5 4
6 5
7 0
8 6
9 1
dtype: int32
3 3
4 2
1 2
6 1
5 1
0 1
dtype: int64
s=pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
s
0 A
1 B
2 C
3 Aaba
4 Baca
5 NaN
6 CABA
7 dog
8 cat
dtype: object
s.str.upper()
0 A
1 B
2 C
3 AABA
4 BACA
5 NaN
6 CABA
7 DOG
8 CAT
dtype: object
df1=pd.DataFrame(np.random.randn(10,4))
df1
|
0 |
1 |
2 |
3 |
| 0 |
-0.932914 |
-1.888419 |
0.382424 |
-0.818447 |
| 1 |
0.610921 |
1.115466 |
-0.198243 |
0.729085 |
| 2 |
0.000842 |
-1.159236 |
0.979033 |
0.375346 |
| 3 |
-0.634415 |
-0.204233 |
2.395083 |
-0.647589 |
| 4 |
-1.354108 |
-0.278728 |
1.042867 |
1.286785 |
| 5 |
0.914505 |
-0.664796 |
1.112920 |
-0.094563 |
| 6 |
-0.167151 |
-1.519254 |
0.015029 |
-0.567899 |
| 7 |
-0.225384 |
-0.293270 |
0.209918 |
-0.205145 |
| 8 |
0.562184 |
-0.706002 |
-0.786689 |
0.780558 |
| 9 |
-0.075450 |
-0.983625 |
-0.053178 |
-1.989312 |
#concat 合并
pieces=[df1[:3],df1[:3]]
pd.concat(pieces)
|
0 |
1 |
2 |
3 |
| 0 |
-0.932914 |
-1.888419 |
0.382424 |
-0.818447 |
| 1 |
0.610921 |
1.115466 |
-0.198243 |
0.729085 |
| 2 |
0.000842 |
-1.159236 |
0.979033 |
0.375346 |
| 0 |
-0.932914 |
-1.888419 |
0.382424 |
-0.818447 |
| 1 |
0.610921 |
1.115466 |
-0.198243 |
0.729085 |
| 2 |
0.000842 |
-1.159236 |
0.979033 |
0.375346 |
left = pd.DataFrame({'key': ['foo', 'bar'], 'lval': [1,2]})
right = pd.DataFrame({'key': ['foo', 'bar'], 'rval': [4,5]})
left
right
pd.merge(left,right,on="key")
|
key |
lval |
rval |
| 0 |
foo |
1 |
4 |
| 1 |
bar |
2 |
5 |
df1
|
0 |
1 |
2 |
3 |
| 0 |
-0.932914 |
-1.888419 |
0.382424 |
-0.818447 |
| 1 |
0.610921 |
1.115466 |
-0.198243 |
0.729085 |
| 2 |
0.000842 |
-1.159236 |
0.979033 |
0.375346 |
| 3 |
-0.634415 |
-0.204233 |
2.395083 |
-0.647589 |
| 4 |
-1.354108 |
-0.278728 |
1.042867 |
1.286785 |
| 5 |
0.914505 |
-0.664796 |
1.112920 |
-0.094563 |
| 6 |
-0.167151 |
-1.519254 |
0.015029 |
-0.567899 |
| 7 |
-0.225384 |
-0.293270 |
0.209918 |
-0.205145 |
| 8 |
0.562184 |
-0.706002 |
-0.786689 |
0.780558 |
| 9 |
-0.075450 |
-0.983625 |
-0.053178 |
-1.989312 |
left.append(right,ignore_index=True)
|
key |
lval |
rval |
| 0 |
foo |
1.0 |
NaN |
| 1 |
bar |
2.0 |
NaN |
| 2 |
foo |
NaN |
4.0 |
| 3 |
bar |
NaN |
5.0 |
df1=pd.DataFrame({"A":["one","two","one","two","one","two","one","two"],"B":np.random.randn(8),"C":[3,4,5,2,1,2,1,2]})
df1.groupby("A").sum()
|
B |
C |
| A |
|
|
| one |
1.358529 |
10 |
| two |
0.522721 |
10 |
df1.groupby(["A","C"]).sum()
|
|
B |
| A |
C |
|
| one |
1 |
0.249465 |
| 3 |
-0.328484 |
| 5 |
1.437548 |
| two |
2 |
-0.171024 |
| 4 |
0.693745 |
df1=pd.DataFrame(np.random.randn(1000,4),index=pd.date_range("20170101",periods=1000),columns=["A","B","C","D"])
df1=df1.cumsum()
df1.plot()
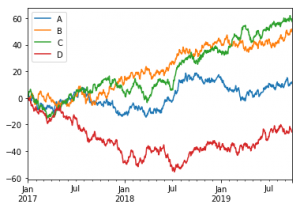
df1=df1.cumsum()
df1.plot()