要理解MySQL幻读问题,就要先搞清楚InnoDB的锁的机制和隔离级别。
MySQL InnoDB事务的隔离级别有四级,默认是“可重复读”(REPEATABLE READ)。
– 未提交读(READ UNCOMMITTED)。另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据(脏读)。
– 提交读(READ COMMITTED)。本事务读取到的是最新的数据(其他事务提交后的)。问题是,在同一个事务里,前后两次相同的SELECT会读到不同的结果(不重复读)。
– 可重复读(REPEATABLE READ)。在同一个事务里,SELECT的结果是事务开始时时间点的状态,因此,同样的SELECT操作读到的结果会是一致的。但是,会有幻读现象(稍后解释)。
– 串行化(SERIALIZABLE)。读操作会隐式获取共享锁,可以保证不同事务间的互斥。
四个级别逐渐增强,每个级别解决一个问题。
- 脏读,最容易理解。另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据。
- 不重复读。解决了脏读后,会遇到,同一个事务执行过程中,另外一个事务提交了新数据,因此本事务先后两次读到的数据结果会不一致。
- 幻读。解决了不重复读,保证了同一个事务里,查询的结果都是事务开始时的状态(一致性)。但是,如果另一个事务同时提交了新数据,本事务再更新时,就会“惊奇的”发现了这些新数据,貌似之前读到的数据是“鬼影”一样的幻觉。
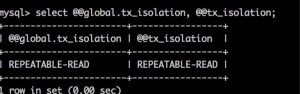
下面开始实验,首先看你数据库的隔离级别
下面开始重复读实验
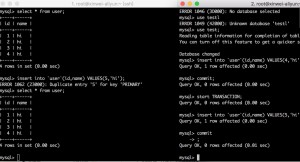
可以看到,左边的事物,查不到ID为5的行,却插不进去,因为这个事物开始的时候,ID为5是不存在的。这就产生了幻读。
怎么解决呢?
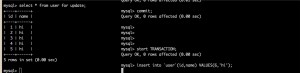
用了for update,这样右边的插入就卡住了,需要等待左边的提交成功后才行。
但是这种会锁表,不知道有没有更好的方法。
参考资料
http://tech.meituan.com/innodb-lock.html