简介
在Git中,用两种方法将两个不同的branch合并。一种是通过git merge,一种是通过git rebase。然而,大部分人都习惯于使用git merge,而忽略git rebase。本文将介绍git rebase的原理、使用方式及应用范围。
git merge 做些什么
当我们在开发一些新功能的时候,往往需要建立新的branch。
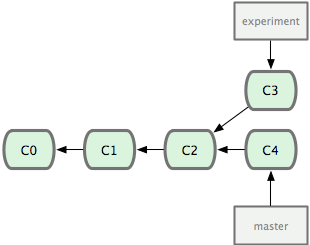
在上图中,每一个绿框均代表一个commit。除了c1,每一个commit都有一条有向边指向它在当前branch当中的上一个commit。
图中的项目,在c2之后就开了另外一个branch,名为experiment。在此之后,master下的修改被放到c4 commit中,experiment下的修改被放到c3 commit中。
如果我们使用merge合并两个分支
$ git checkout master
$ git merge experiment
得到的commit log如下图所示
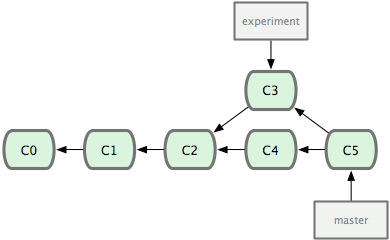
我们看到,merge所做的事情实际上是:
- 首先找到
master和experiment中最新的commit的最近公共祖先,在这里就是c4和c3的最近公共祖先c2。 - 将
experiment分支上在c2以后的所有commit合并成一个commit,并与master合并 - 如有合并冲突(两个分支修改了同一个文件),首先人工去除重复。
- 在master上产生合并后的新commit
git rebase做些什么
rebase所做的事情也是合并两个分支,但是它的方式略有不同。基于上例描述,rebase的工作流程是
- 首先找到
master和experiment中最新的commit的最近公共祖先,在这里就是c4和c3的最近公共祖先c2。 - 将
experiment分支上在c2以后的所有commit*全部移动到*master分支的最新commit之后,在这里就是把c3移动到c4以后。
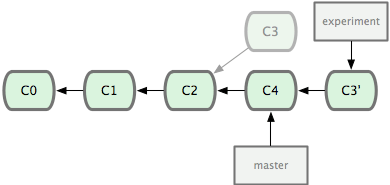
由于git的每一个commit都只存储相对上一个commit的变化(或者说是差值,delta)。我们通过移动c3到master,代表着在master上进行c3相应的修改。为了达成这一点,只需在experiment分支上rebase master
$ git checkout experiment
$ git rebase master
需要注意的是,rebase并不是直接将c3移动到master上,而是创建一个副本。我们可以通过实际操作发现这一点。在rebase前后,c3的hash code是不一样的。
rebase前的commit log是
* 1b4c6d6 (master) <- c4
| * 66c417b (experiment) <- c3
|/
* 972628d
rebase后的commit log是
* d9eeb1a - (experiment) <- c3'
* 1b4c6d6 - (master) <- c4
* 972628d
可以发现c3的hash code从66c417b变到了d9eeb1a。
在这之后,我们只需要在master上进行一次前向合并(fast-forward merge)
$ git checkout master
$ git merge experiment
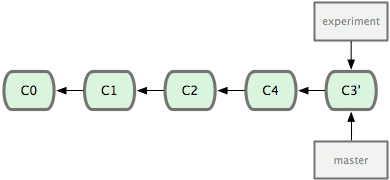
rebase之后的commit log呈线性,更加清晰。此时如果experiment分支不再被需要,我们可以删除它。
$ git branch -d experiment
何时使用
我们一般只在本地开发的时候rebase一个自己写出来的branch。
谨记,千万不要rebase一个已经发布到远程git服务器的分支。例如,你如果将分支experiment发布到了GitHub,那么你就不应该将它rebase到master上。因为如果你将它rebase到master上,将对其他人造成麻烦。
总结
git rebase帮助我们避免merge带来的复杂commit log,允许以线性commit的形式进行分支开发。